출처
- 해당 포스트는 정수원 강사님의 스프링 배치 - Spring Boot 기반으로 개발하는 Spring Batch 강의를 바탕으로 작성 됐습니다.
목차
- [Spring Batch] - ItemWriter
- [Spring Batch] - ItemProcessor
- [Spring Batch] - ItemReader
- [Spring Batch] - ChunkProvider 와 ChunkProcessor
- [Spring Batch] - ChunkOrientedTasklet
- [Spring Batch] - Chunk 기반 Step
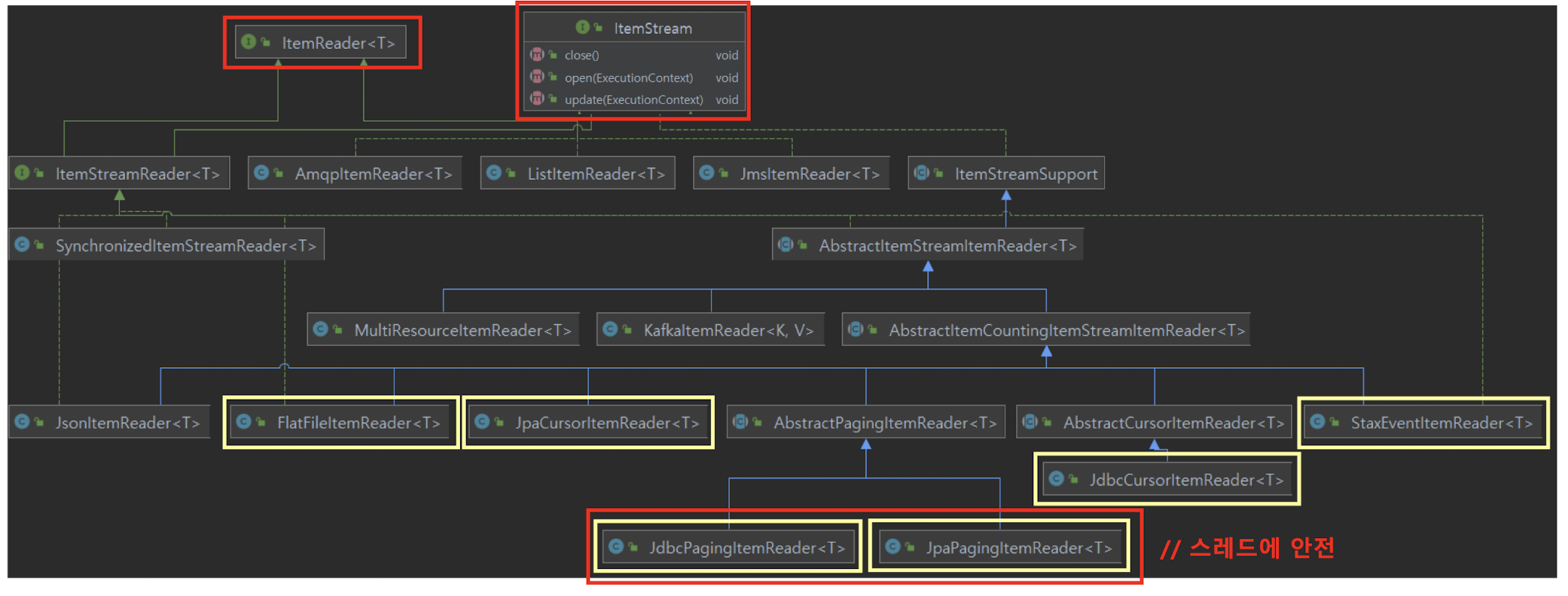
ItemReader
ItemReader 는 스텝 내에서 사용될 데이터를 읽는 역할을 합니다. ItemReader 는 스텝이 시작될 때 호출되며, 데이터 소스에서 데이터를 읽어 Chunk 단위로 ItemProcessor에 전달합니다.
ItemReader는 일반적으로 파일, 데이터베이스 또는 메시징 시스템과 같은 외부 데이터 소스에서 데이터를 읽는 데 사용됩니다. Spring Batch는 다양한 유형의 ItemReader를 지원하며, 일반적으로 사용되는 ItemReader 유형은 다음과 같습니다.
ItemReader 구현체
- FlatFileItemReader: CSV, 고정 길이 또는 구분 기호로 구분된 파일에서 데이터를 읽는 데 사용됩니다.
- JdbcCursorItemReader: JDBC 쿼리를 실행하고 ResultSet에서 데이터를 읽는 데 사용됩니다.
- JpaPagingItemReader: JPA를 사용하여 페이징 처리를 수행하고 데이터를 읽는 데 사용됩니다.
- StaxEventItemReader: XML 데이터를 읽는 데 사용됩니다.
- JmsItemReader: JMS 대기열에서 데이터를 읽는 데 사용됩니다.
다수의 구현체들이 ItemReader 와 ItemStream 을 동시에 구현하고 있습니다. ItemStream 은 파일의 스트림을 열거나 종료, DB 커넥션을 열거나 종료, 출력 장치 초기화 등의 작업을 진행합니다.
ItemReader 인터페이스
public interface ItemReader<T> { |