목차
🤔 대용량 조회 시 애플리케이션과 데이터베이스는 어떻게 동작하는가?
대용량 데이터를 조회해야 하는 상황이 생기면, 우리는 종종 “애플리케이션 메모리는 괜찮을까?”, “DB에 부하가 가지는 않을까?” 같은 고민을 하게 됩니다.
자바 JDBC 에서는 이런 상황을 제어하기 위해 cursor 와 fetch size 를 이용합니다.
🕵️♂️ 대용량 조회의 기본 흐름
JDBC로 쿼리를 실행할 때, 결과가 수천~수만 건이라면 어떻게 처리될까요? 예를 들어, 아래 코드를 실행했다고 가정해 봅시다.
PreparedStatement ps = conn.prepareStatement("SELECT * FROM large_table"); |
이 코드가 실행될 때 내부적으로 일어나는 동작은 아래와 같습니다
- 애플리케이션이 DB에 쿼리를 날립니다.
- DB는 전체 결과를 준비하고 커서를 생성합니다.
- JDBC 드라이버는 커서로부터 100 건씩 row 를 가져옴니다
- row 를 다 소비하면 JDBC는 다음 100 건을 요청합니다.
- 이 과정을 반복하여 전체 데이터를 처리합니다.
어플리케이션에서 쿼리를 데이터베이스에 날리게 되면 쿼리는 1번만 실행되고, 데이터는 설정한 fetch size 단위로 반복적으로 가져옵니다.
🔎 fetch size 란 무엇인가?
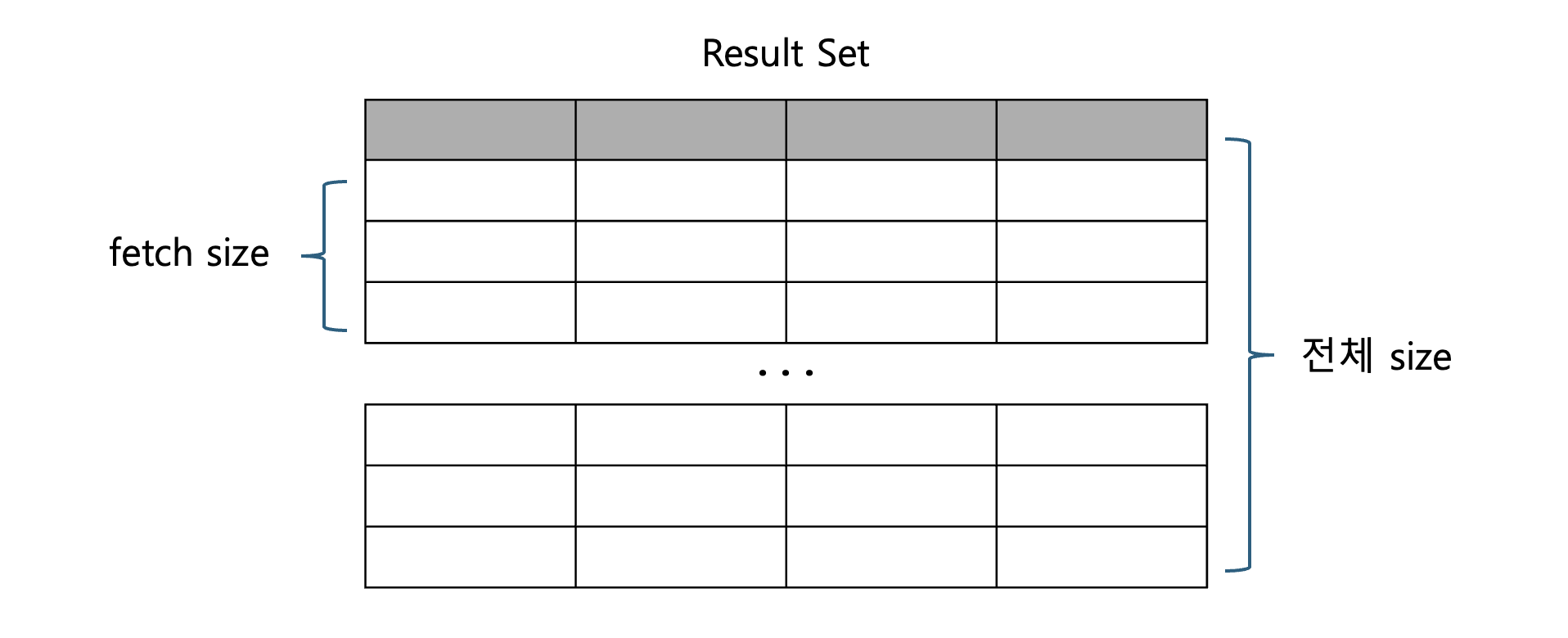
fetch size는 Cursor 를 이용해 데이터 베이스에서 한 번에 가져오는 Row 의 개수
fetch 는 데이터베이스로 부터 데이터를 가져오는 작업입니다. fetch size 란 데이터로부터 한번에 가져오는 row 의 개수를 의미합니다. 이때 cursor 를 이용해 cursor 가 가르키고 있는 위치로부터 지정한 size 만큼의 데이터를 읽어 반환합니다. 예를 들어, JDBC 에서는 fetch size 가 100 이라면, 전체데이터에서 100건씩 커서를 이용해 읽어옵니다.
이렇게 하면 메모리에 모든 row를 올리지 않아도 되기 때문에 메모리 효율이 좋아지고, 너무 잦은 DB 통신도 막을 수 있어서 성능 최적화에 도움이 됩니다.
🔎 fetch size 만큼 쿼리가 여러 번 수행되는가?
전체 데이터가 만건이고 fetch size 가 100 이면 쿼리가 100번 실행될까 하는 의문이 있을 수 있습니다. 하지만, 쿼리를 통해 가져올 데이터 셋이 정해지면 데이터 베이스는 cursor 를 이용해 결과를 fetch size 만큼 나눠서 가져오는 개념이므로 애플리케이션과 DB 간의 데이터 통신은 가져올 수만큼 발생하나 쿼리는 한번만 실행됩니다.